
Like most other internet-connected people, I have seen the increase in AI-generated content in recent months. ChatGPT is fun to use and I’m sure there are plenty of useful use cases for it but I’m not sure I have the imagination required to use it to it’s full potential. The AI art fad of a couple months ago was cool too. In the back of my mind, I kept thinking “where will AI take us in the next couple years”. I still don’t know the answer to that. The only “art” I am good at is pottery (thanks to high-school pottery class – I took 4 semesters of it and had a great time doing so, whole different story). But now I’m able to generate my own AI art thanks to a guide I found the other day on /g/. I am re-writing it here with screenshots and a bit more detail to try and make it more accessible to general users.
NOTE: You need a decent/recent Nvidia GPU to follow this guide. I have a RTX 2080 Super with 8GB of VRAM. There are low-memory workarounds but I haven’t tested them yet. An absolute limit is 2GB VRAM, and a GTX 7xx (Maxwell architecture) or newer GPU.
Stable Diffusion Tutorial Contents
- Installing Python 3.10
- Installing Git (the source control system)
- Clone the Automatic1111 web UI (this is the front-end for using the various models)
- Download models
- Adjust memory limits & enable listening outside of localhost
- First run
- Launching the web UI
- Generating Stable Diffusion images
Video version of this install guide
Coming soon. I always do the written guide first, then record based off the written guide. Hopefully by end of day (mountain time) Feb 24.
1 – Installing Python 3.10
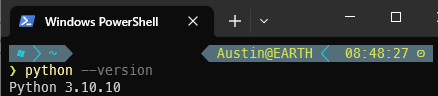
This is relatively straight-forward. To check your Python version, go to a command line and enter
python --version
If you already have Python 3.10.x installed (as seen in the screenshot below), you’re good to go (minor version doesn’t matter).
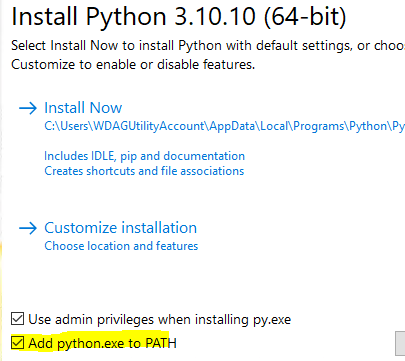
If not, go to the Python 3 download page and select the most recent 3.10 version. As of writing, the most recent is 3.10.10. Download the x64 installer and install. Ensure the “add python.exe to PATH” checkbox is checked. Adding python.exe to PATH means it can be called with only python at a command prompt instead of the full path, which is something like c:/users/whatever/somedirectory/moredirectories/3.10.10/python.exe.
2 – Installing Git (the source control system)
This is easier than Python – just install it – https://git-scm.com/downloads. Check for presence and version with git –version:

3 – Clone the Automatic1111 web UI (this is the front-end for using the various models)
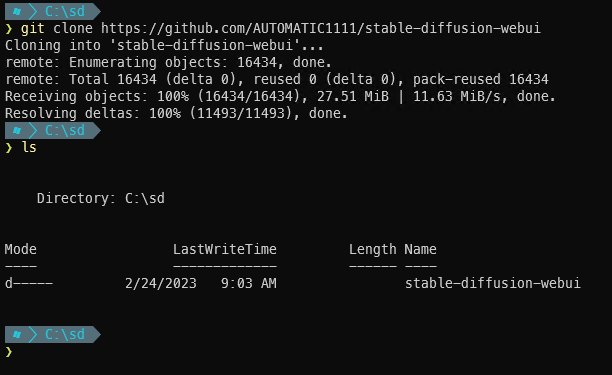
With Git, clone means to download a copy of the code repository. When you clone a repo, a new directory is created in whatever directory the command is run in. Meaning that if you navigate to your desktop, and run git clone xyz, you will have a new folder on your desktop named xyz with the contents of the repository. To keep things simple, I am going to create a folder for all my Stable Diffusion stuff in the C:/ root named sd and then clone into that folder.
Open a command prompt and enter
cd c:\
Next create the sd folder and enter it:
mkdir sd cd sd
Now clone the repository while in your sd folder:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
After the git clone completes, there will be a new directory called ‘stable-diffusion-webui’:
4 – Download models
“Models” are what actually generate the content based on provided prompts. Generally, you will want to use pre-trained models. Luckily, there are many ready to use. Training your own model is far beyond the scope of this basic installation tutorial. Training your own models generally also requires huge amounts of time crunching numbers on very powerful GPUs.
As of writing, Stable Diffusion 1.5 (SD 1.5) is the recommended model. It can be downloaded (note: this is a 7.5GB file) from huggingface here.
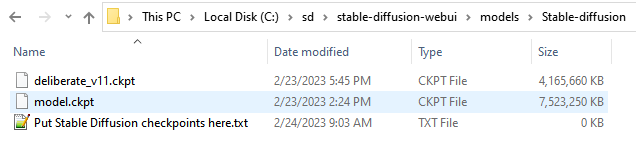
Take the downloaded file, and place it in the stable-diffusion-webui/models/Stable-diffusion directory and rename it to model.ckpt (it can be named anything you want but the web UI automatically attempts to load a model named ‘model.ckpt’ upon start). If you’re following along with the same directory structure as me, this file will end up at C:\sd\stable-diffusion-webui\models\Stable-diffusion\model.ckpt.
Another popular model is Deliberate. It can be downloaded (4.2GB) here. Put it in the same folder as the other model. No need to rename the 2nd (and other) models.
After downloading both models, the directory should look like this:
5 – Adjust memory limits & enable listening outside of localhost (command line arguments)
Inside the main stable-diffusion-webui directory live a number of launcher files and helper files. Find webui-user.bat and edit it (.bat files can be right-clicked -> edit).
Add –medvram (two dashes) after the equals sign of COMMANDLINE_ARGS. If you also want the UI to listen on all IP addresses instead of just localhost (don’t do this unless you know what that means), also add –listen.
webui-user.bat after edits
@echo off set PYTHON= set GIT= set VENV_DIR= set COMMANDLINE_ARGS=--listen --medvram call webui.bat
6 – First run
The UI tool (developed by automatic1111) will automatically download a variety of requirements upon first launch. It will take a few minutes to complete. Double-click the webui-user.bat file we just edited. It calls a few .bat files and eventually launches a Python file. The .bat files are essentially glue to stick a bunch of stuff together for the main file.
The very first thing it does is creates a Python venv (virtual environment) to keep the Stable Diffusion packages separate from your other Python packages. Then it pip installs a bunch of packages related to cuda/pytorch/numpy/etc so Python can interact with your GPU.
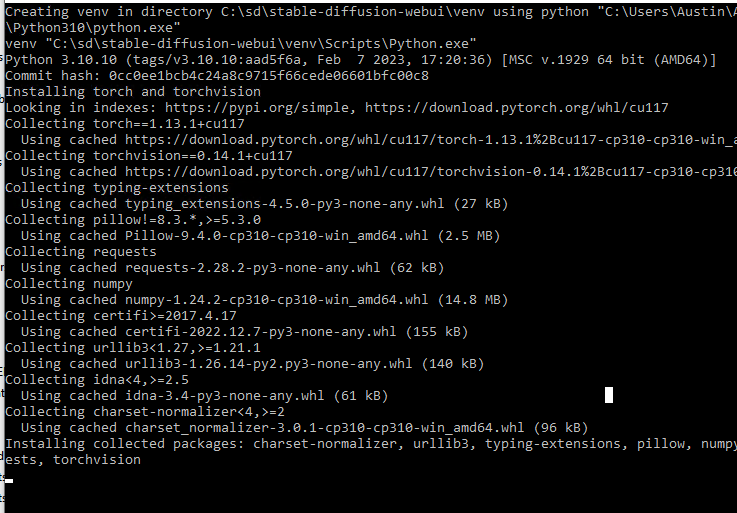
After everything is installed and ready to go, you will see a line that says: Running on local URL: http://127.0.0.1:7860. That means the Python web server UI is running on your own computer on port 7860 (if you added –listen to the launch args, it will show 0.0.0.0:7860, which means it is listening on all IP addresses and can be accessed by external machinse).
7 – Launching the web UI
With the web UI server running, it can be accessed via browser on the same computer running the Python at http://127.0.0.1:7860. That link should work for you if you click it.
Note that if the Python process closes for whatever reason (you close the command window, your computer reboots, etc), you need to double-click webui-user.bat to relaunch it and it needs to be running any time you want to access the web UI.
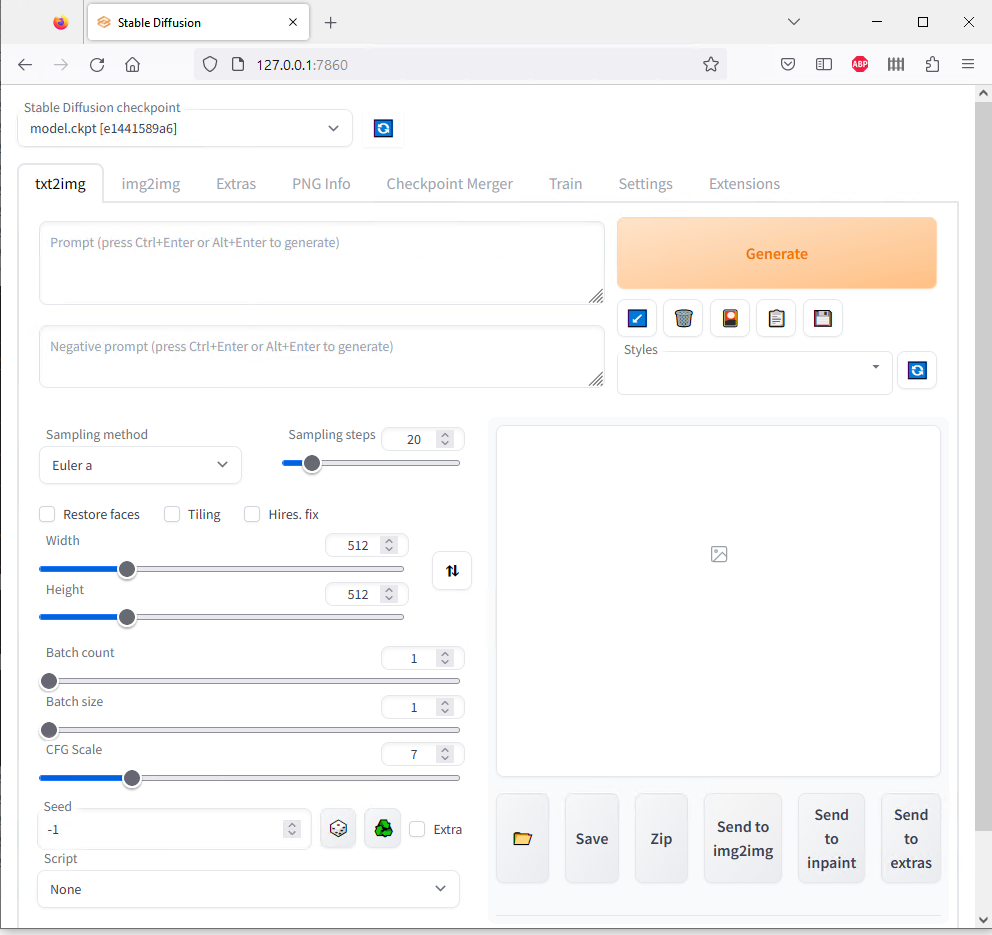
As seen in the screenshot, there are a ton of parameters/settings. I’ll highlight a few in the next section
8 – Generating Stable Diffusion images
This is the tricky part. The prompts make or break your generation. I am still learning. The prompt is where you enter what you want to see. Negative prompt is where you enter what you don’t want to see.
Let’s start simple, with cat in the prompt. Then click generate. A very reasonable-looking cat should soon appear (typically takes a couple seconds per image):

To highlight a few of the settings/sliders:
- Stable diffusion checkpoint – model selector. Note that it’ll take a bit to load a new model (the multi-GB files need to be read in their entirety and ingested).
- Prompt – what you want to see
- Negative prompt – what you don’t want to see
- Sampling method – various methods to sample new points
- Sampling steps – how many iterations to use for image generation for a single image
- Width – width of image to generate (in pixels). NOTE, you need a very powerful GPU with a ton of VRAM to go much higher than the default 512
- Height – height of image to generate (in pixels). Same warning applies as width
- Batch count – how many images to include in a batch generation
- Batch size – haven’t used yet, presumably used to specify how many batches to generate
- CFG Scale – this slider tells the models how specific they need to be for the prompt. Higher is more specific. Really high values (>12ish) start to get a bit abstract. Probably want to be in the range of 3-10 for this slider.
- Seed – random number generator seed. -1 means use a new seed for every image.
Some thoughts on prompt/negative prompt
From my ~24 hours using this tool, it is very clear that prompt/negative prompts are what make or break your generation. I think that your ability as a pre-AI artist would come in handy here. I am no artist so I have a hard time putting what I want to see into words. Take example prompt: valley, fairytale treehouse village covered, matte painting, highly detailed, dynamic lighting, cinematic, realism, realistic, photo real, sunset, detailed, high contrast, denoised, centered. I would’ve said “fairytale treehouse” and stopped at that. Compare the two prompts below with the more detailed prompt directly below and the basic “fairytale treehouse” prompt after that:


One of these looks perfectly in place for a fantasy story. The other you could very possibly see in person in a nearby forest.
Both positive and negative can get very long very quickly. Many of the AI-generated artifacts present over the last month or two can be eliminated with negative prompt entries.
Example negative prompt: ugly, deformed, malformed, lowres, mutant, mutated, disfigured, compressed, noise, artifacts, dithering, simple, watermark, text, font, signage, collage, pixel
I will not pretend to know what works well vs not. Google is your friend here. I believe that “prompt engineering” will be very important in AI’s future. Google is your friend here.
Conclusion
AI-generated content is here. It will not be going away. Even if it is outlawed, the code is out there. AI will be a huge part of our future, regardless of if you want it or not. As the saying goes – pandora’s box is now open.
I figured it was worth trying. The guide this is based off made it relatively easy for me (but I do have above-average computer skill), and I wanted to make it even easier. Hopefully you found this ‘how to set up stable diffusion’ guide easy to use as well. Please let me know in the comments section if you have any questions/comments/feedback – I check at least daily!
Resources
Huge shout out to whoever wrote the guide (“all anons”) at https://rentry.org/voldy. That is essentially where this entire guide came from.
Disclosure: When you click on links to various merchants in this post and make a purchase, this can result in this site earning a commission. Affiliate programs and affiliations include, but are not limited to, the eBay Partner Network.
One reply on “Stable Diffusion Tutorial – Nvidia GPU Installation”
Thanks for this detailed walkthrough! Installing Automatic1111 locally is great if you have a powerful GPU like the one you mentioned. For those who might be limited by hardware or looking for a cloud-based solution to integrate into their own apps, using a Stable Diffusion API can be a real time-saver. Great guide for getting the local environment set up!