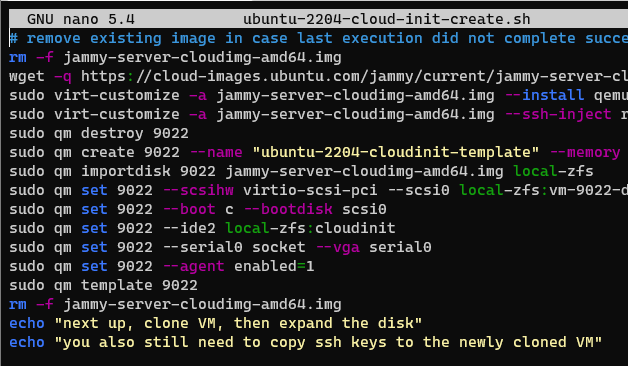
Been a while since I last posted. For basically everything I do Linux-wise, I use Ubuntu. Specifically the Long Term Support versions, which are released on even years in April (April 2020, April 2022, etc.), hence the 22.04 designation of the latest LTS, Jammy. I had standardized on 20.04 (Focal) for everything, but am finding that various packages I use that I expect to be available on 20.04, aren’t. But they are present in standard, default package lists for Jammy 22.04. Last night I was creating a new VM to transfer this very blog to my shiny, new co-located server. I was going to use the Ubuntu 20.04 Proxmox Cloud Init Image Script template I wrote up a bit ago. Then I stopped and realized I should update it. So I changed 2004 everywhere in the script to 2204 and ‘focal’ to ‘jammy’, reran it, and now I have a fancy new cloud init script for Ubuntu 22.04. Note that this script does require you to install libguestfs-tools, as indicated in the previous cloud-init post.
ChatGPT enhanced script as of 2023:
#!/bin/bash
##############################################################################
# things to double-check:
# 1. user directory
# 2. your SSH key location
# 3. which bridge you assign with the create line (currently set to vmbr100)
# 4. which storage is being utilized (script uses local-zfs)
##############################################################################
DISK_IMAGE="jammy-server-cloudimg-amd64.img"
IMAGE_URL="https://cloud-images.ubuntu.com/jammy/current/$DISK_IMAGE"
# Function to check if a file was modified in the last 24 hours or doesn't exist
should_download_image() {
local file="$1"
# If file doesn't exist, return true (i.e., should download)
[[ ! -f "$file" ]] && return 0
local current_time=$(date +%s)
local file_mod_time=$(stat --format="%Y" "$file")
local difference=$(( current_time - file_mod_time ))
# If older than 24 hours, return true
(( difference >= 86400 ))
}
# Download the disk image if it doesn't exist or if it was modified more than 24 hours ago
if should_download_image "$DISK_IMAGE"; then
rm -f "$DISK_IMAGE"
wget -q "$IMAGE_URL"
fi
sudo virt-customize -a "$DISK_IMAGE" --install qemu-guest-agent
sudo virt-customize -a "$DISK_IMAGE" --ssh-inject root:file:/home/austin/id_rsa.pub
if sudo qm list | grep -qw "9022"; then
sudo qm destroy 9022
fi
sudo qm create 9022 --name "ubuntu-2204-cloudinit-template" --memory 2048 --cores 2 --net0 virtio,bridge=vmbr100
sudo qm importdisk 9022 "$DISK_IMAGE" local-zfs
sudo qm set 9022 --scsihw virtio-scsi-pci --scsi0 local-zfs:vm-9022-disk-0
sudo qm set 9022 --boot c --bootdisk scsi0
sudo qm set 9022 --ide2 local-zfs:cloudinit
sudo qm set 9022 --serial0 socket --vga serial0
sudo qm set 9022 --agent enabled=1
sudo qm template 9022
echo "Next up, clone VM, then expand the disk"
echo "You also still need to copy ssh keys to the newly cloned VM"
Original, non-ChatGPT script:
###############
# things to double-check:
# 1. user directory
# 2. your SSH key location
# 3. which bridge you assign with the create line (currently set to vmbr100)
# 4. which storage is being utilized (script uses local-zfs)
###############
rm -f jammy-server-cloudimg-amd64.img
wget -q https://cloud-images.ubuntu.com/jammy/current/jammy-server-cloudimg-amd64.img
sudo virt-customize -a jammy-server-cloudimg-amd64.img --install qemu-guest-agent
sudo virt-customize -a jammy-server-cloudimg-amd64.img --ssh-inject root:file:/home/austin/id_rsa.pub
sudo qm destroy 9022
sudo qm create 9022 --name "ubuntu-2204-cloudinit-template" --memory 2048 --cores 2 --net0 virtio,bridge=vmbr100
sudo qm importdisk 9022 jammy-server-cloudimg-amd64.img local-zfs
sudo qm set 9022 --scsihw virtio-scsi-pci --scsi0 local-zfs:vm-9022-disk-0
sudo qm set 9022 --boot c --bootdisk scsi0
sudo qm set 9022 --ide2 local-zfs:cloudinit
sudo qm set 9022 --serial0 socket --vga serial0
sudo qm set 9022 --agent enabled=1
sudo qm template 9022
rm -f jammy-server-cloudimg-amd64.img
echo "next up, clone VM, then expand the disk"
echo "you also still need to copy ssh keys to the newly cloned VM"
Proxmox Ubuntu 22.04 cloud-init image script
I suppose for a full automation I should get user with a whoami command, assign it to a variable, and use that throughout the script. That’s a task for another day.
I also added a line in my crontab to have this script run weekly, so the image is essentially always up to date. I’ll run both 20.04 and 22.04 in parallel for a bit but anticipate that I can turn off the 20.04 job fairly soon.
# m h dom mon dow command
52 19 * * TUE sleep $(( RANDOM \% 60 )); /usr/bin/bash /home/austin/ubuntu-2004-cloud-init-create.sh >> /home/austin/ubuntu-template.log 2>&1
52 20 * * TUE sleep $(( RANDOM \% 60 )); /usr/bin/bash /home/austin/ubuntu-2204-cloud-init-create.sh >> /home/austin/ubuntu-2204-template.log 2>&1
Sometimes I make a change to my Proxmox cluster configuration without all nodes in a healthy state (i.e. they are off). This isn’t a great habit to get into and sometimes results in troubleshooting.
Putting a quick post up so I can easily reference how to resolve corosync issues.
# stop corosync and pmxcfs on all nodes
$ systemctl stop corosync pve-cluster
# start pmxcfs in local mode on all nodes
$ pmxcfs -l
# put correct corosync config into local pmxcfs and corosync config dir (make sure to bump the 'config_version' inside the config file)
$ cp correct_corosync.conf /etc/pve/corosync.conf
$ cp correct_corosync.conf /etc/corosync/corosync.conf
# kill local pmxcfs
$ killall pmxcfs
# start corosync and pmxcfs again
$ systemctl start pve-cluster corosync
# check status
$ journalctl --since '-5min' -u pve-cluster -u corosync
$ pvecm status
This post has been a long time coming. I apologize for how long it’s taken. I noticed that many other blogs left off at a similar position as I did. Get the VMs created then…. nothing. Creating a Kubernetes cluster locally is a much cheaper (read: basically free) option to learn how Kubes works compared to a cloud-hosted solution or a full-blown Kubernetes engine/solution, such as AWS Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), or Google Kubernetes Engine (GKE).
Anyways, I finally had some time to complete the tutorial series so here we are. Since the last post, my wife and I are now expecting our 2nd kid, I put up a new solar panel array, built our 1st kid a new bed, messed around with MacOS Monterey on Proxmox, built garden boxes, and a bunch of other stuff. Life happens. So without much more delay let’s jump back in.
Here’s a screenshot of the end state Kubernetes Dashboard showing our nodes:
Kubernetes Dashboard showing our Proxmox VM nodes deployed via Terraform
Current State
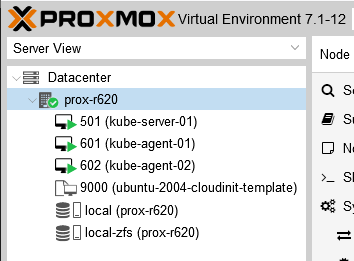
If you’ve followed the blog series so far, you should have four VMs in your Proxmox cluster ready to go with SSH keys set, the hard drive expanded, and the right amount of vCPUs and memory allocated. If you don’t have those ready to go, take a step back (Deploying Kubernetes VMs in Proxmox with Terraform) and get caught up. We’re not going to use the storage VM. Some guides I followed had one but I haven’t found a need for it yet so we’ll skip it.
VMs in Proxmox ready for Kubernetes installation
Ansible
What is Ansible
If you ask DuckDuckGo to define ansible, it will tell you the following: “A hypothetical device that enables users to communicate instantaneously across great distances; that is, a faster-than-light communication device.”
We will thus be using Ansible to run the initial Kubernetes set up steps on every machine, initialize the cluster on the master, and join the cluster on the workers/agents.
Initial Ansible Housekeeping
First we need to specify some variables similar to how we did it with Terraform. Create a file in your working directory called ansible-vars.yml and put the following into it:
# specifying a CIDR for our cluster to use.
# can be basically any private range except for ranges already in use.
# apparently it isn't too hard to run out of IPs in a /24, so we're using a /22
pod_cidr: "10.16.0.0/22"
# this defines what the join command filename will be
join_command_location: "join_command.out"
# setting the home directory for retreiving, saving, and executing files
home_dir: "/home/ubuntu"
Equally as important (and potentially a better starting point than the variables) is defining the hosts. In ansible-hosts.txt:
# this is a basic file putting different hosts into categories
# used by ansible to determine which actions to run on which hosts
[all]
10.98.1.41
10.98.1.51
10.98.1.52
[kube_server]
10.98.1.41
[kube_agents]
10.98.1.51
10.98.1.52
[kube_storage]
#10.98.1.61
Checking Ansible can communicated with our hosts
Let’s pause here and make sure Ansible can communicate with our VMs. We will use a simple built-in module named ‘ping’ to do so. The below command broken down:
-i ansible-hosts.txt – use the ansible-hosts.txt file
all – run the command against the [all] block from the ansible-hosts.txt file
-u ubuntu – log in with user ubuntu (since that’s what we set up with the Ubuntu 20.04 Cloud Init template). if you don’t use -u [user], it will use your currently logged in user to attempt to SSH.
-m ping – run the ping module
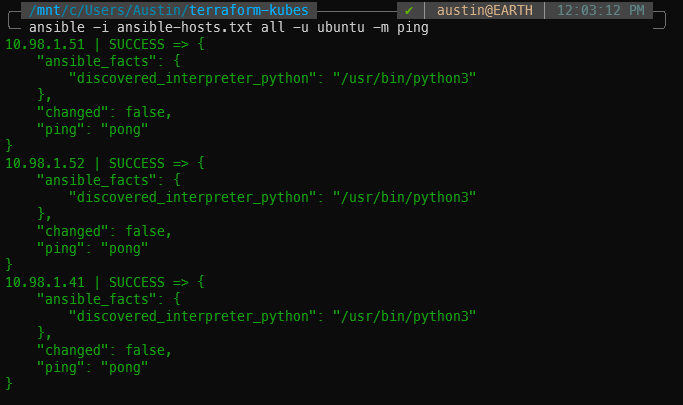
ansible -i ansible-hosts.txt all -u ubuntu -m ping
If all goes well, you will receive “ping”: “pong” for each of the VMs you have listed in the [all] block of the ansible-hosts.txt file.
Using Ansible’s ping to check communications with each of the VMs for deployment
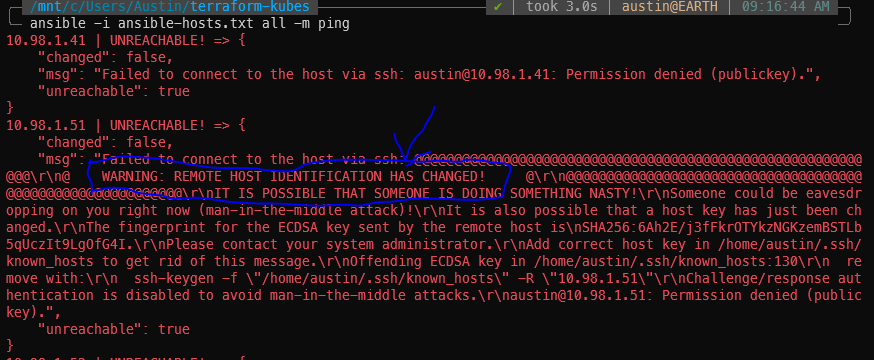
Potential SSH errors
If you’ve previously SSH’d to these IPs and have subsequently destroyed/re-created them, you will get scary sounding SSH errors about remote host identification has changed. Run the suggested ssh-keygen -f command for each of the IPs to fix it.
You might also have to SSH into each of the hosts to accept the host key. I’ve done this whole procedure a couple times so I don’t recall what will pop up first attempt.
SSH remote host identification has changed error. Run suggested ssh-keygen -f command to resolve.
Then we need a script to install the dependencies and the Kubernetes utilities themselves. This script does quite a few things. Gets apt ready to install things, adding the Docker & Kubernetes signing key, installing Docker and Kubernetes, disabling swap, and adding the ubuntu user to the Docker group.
ansible-install-kubernetes-dependencies.yml:
# https://kubernetes.io/blog/2019/03/15/kubernetes-setup-using-ansible-and-vagrant/
# https://github.com/virtualelephant/vsphere-kubernetes/blob/master/ansible/cilium-install.yml#L57
# ansible .yml files define what tasks/operations to run
---
- hosts: all # run on the "all" hosts category from ansible-hosts.txt
# become means be superuser
become: true
remote_user: ubuntu
tasks:
- name: Install packages that allow apt to be used over HTTPS
apt:
name: "{{ packages }}"
state: present
update_cache: yes
vars:
packages:
- apt-transport-https
- ca-certificates
- curl
- gnupg-agent
- software-properties-common
- name: Add an apt signing key for Docker
apt_key:
url: https://download.docker.com/linux/ubuntu/gpg
state: present
- name: Add apt repository for stable version
apt_repository:
repo: deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable
state: present
- name: Install docker and its dependecies
apt:
name: "{{ packages }}"
state: present
update_cache: yes
vars:
packages:
- docker-ce
- docker-ce-cli
- containerd.io
- name: verify docker installed, enabled, and started
service:
name: docker
state: started
enabled: yes
- name: Remove swapfile from /etc/fstab
mount:
name: "{{ item }}"
fstype: swap
state: absent
with_items:
- swap
- none
- name: Disable swap
command: swapoff -a
when: ansible_swaptotal_mb >= 0
- name: Add an apt signing key for Kubernetes
apt_key:
url: https://packages.cloud.google.com/apt/doc/apt-key.gpg
state: present
- name: Adding apt repository for Kubernetes
apt_repository:
repo: deb https://apt.kubernetes.io/ kubernetes-xenial main
state: present
filename: kubernetes.list
- name: Install Kubernetes binaries
apt:
name: "{{ packages }}"
state: present
update_cache: yes
vars:
packages:
# it is usually recommended to specify which version you want to install
- kubelet=1.23.6-00
- kubeadm=1.23.6-00
- kubectl=1.23.6-00
- name: hold kubernetes binary versions (prevent from being updated)
dpkg_selections:
name: "{{ item }}"
selection: hold
loop:
- kubelet
- kubeadm
- kubectl
# this has to do with nodes having different internal/external/mgmt IPs
# {{ node_ip }} comes from vagrant, which I'm not using yet
# - name: Configure node ip -
# lineinfile:
# path: /etc/default/kubelet
# line: KUBELET_EXTRA_ARGS=--node-ip={{ node_ip }}
- name: Restart kubelet
service:
name: kubelet
daemon_reload: yes
state: restarted
- name: add ubuntu user to docker
user:
name: ubuntu
group: docker
- name: reboot to apply swap disable
reboot:
reboot_timeout: 180 #allow 3 minutes for reboot to happen
With our fresh VMs straight outta Terraform, let’s now run the Ansible script to install the dependencies.
Ansible command to run the Kubernetes dependency playbook (pretty straight-forward: the -i is to input the hosts file, then the next argument is the playbook file itself):
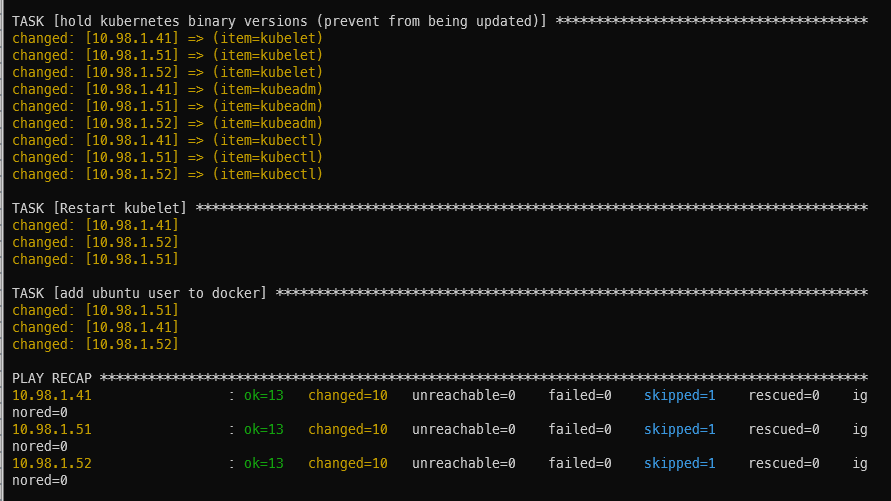
It’ll take a bit of time to run (1m26s in my case). If all goes well, you will be presented with a summary screen (called PLAY RECAP) showing some items in green with status ok and some items in orange with status changed. I got 13 ok’s, 10 changed’s, and 1 skipped.
Ansible play recap showing successful Kubernetes dependencies installation
Initialize the Kubernetes cluster on the master
With the dependencies installed, we can now proceed to initialize the Kubernetes cluster itself on the server/master machine. This script sets docker to use systemd cgroups driver (don’t recall what the alternative is at the moment but this was the easiest of the alternatives), initializes the cluster, copies the cluster files to the ubuntu user’s home directory, installs Calico networking plugin, and the standard Kubernetes dashboard.
ansible-init-cluster.yml:
- hosts: kube_server
become: true
remote_user: ubuntu
vars_files:
- ansible-vars.yml
tasks:
- name: set docker to use systemd cgroups driver
copy:
dest: "/etc/docker/daemon.json"
content: |
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
- name: restart docker
service:
name: docker
state: restarted
- name: Initialize Kubernetes cluster
command: "kubeadm init --pod-network-cidr {{ pod_cidr }}"
args:
creates: /etc/kubernetes/admin.conf # skip this task if the file already exists
register: kube_init
- name: show kube init info
debug:
var: kube_init
- name: Create .kube directory in user home
file:
path: "{{ home_dir }}/.kube"
state: directory
owner: 1000
group: 1000
- name: Configure .kube/config files in user home
copy:
src: /etc/kubernetes/admin.conf
dest: "{{ home_dir }}/.kube/config"
remote_src: yes
owner: 1000
group: 1000
- name: restart kubelet for config changes
service:
name: kubelet
state: restarted
- name: get calico networking
get_url:
url: https://projectcalico.docs.tigera.io/manifests/calico.yaml
dest: "{{ home_dir }}/calico.yaml"
- name: apply calico networking
become: no
command: kubectl apply -f "{{ home_dir }}/calico.yaml"
- name: get dashboard
get_url:
url: https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.0/aio/deploy/recommended.yaml
dest: "{{ home_dir }}/dashboard.yaml"
- name: apply dashboard
become: no
command: kubectl apply -f "{{ home_dir }}/dashboard.yaml"
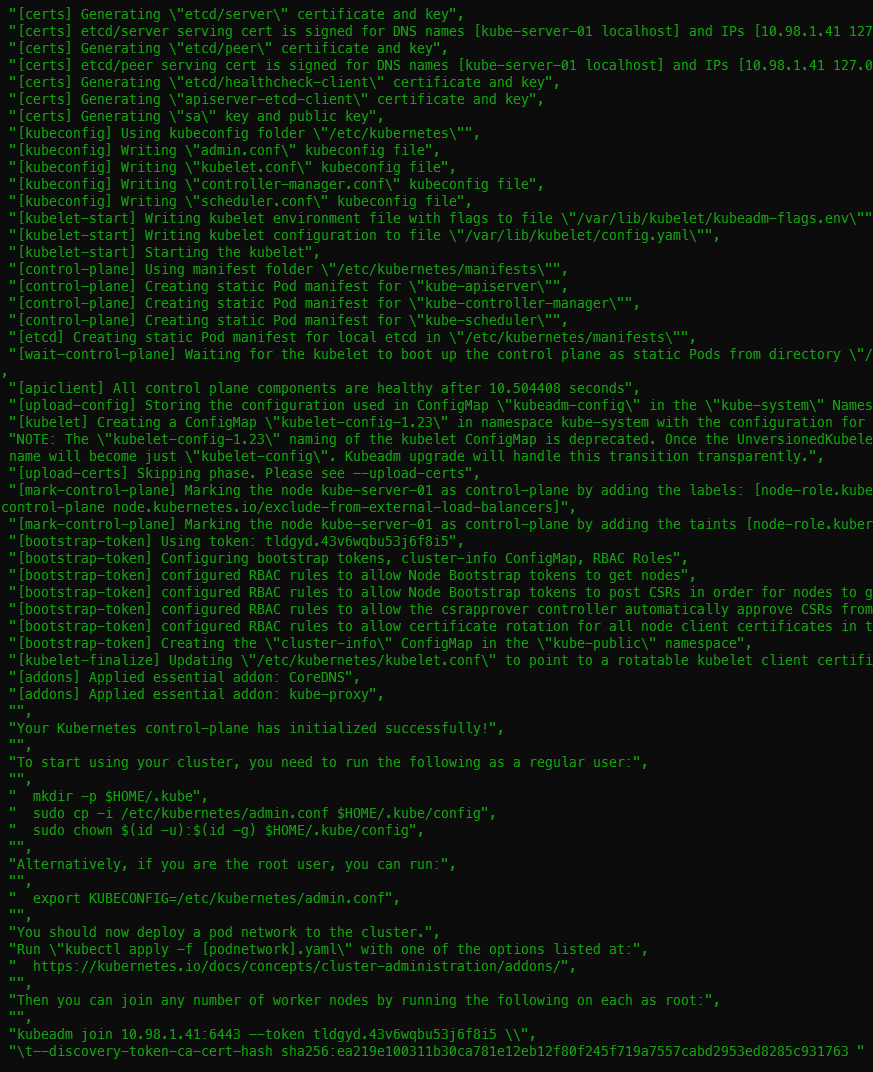
Initializing the cluster took 53s on my machine. One of the first tasks is to download the images which takes the majority of the duration. You should get 13 ok and 10 changed with the init. I had two extra user check tasks because I was fighting some issues with applying the Calico networking.
Successful Kubernetes init execution showing join token at the bottom
Getting the join command and joining worker nodes
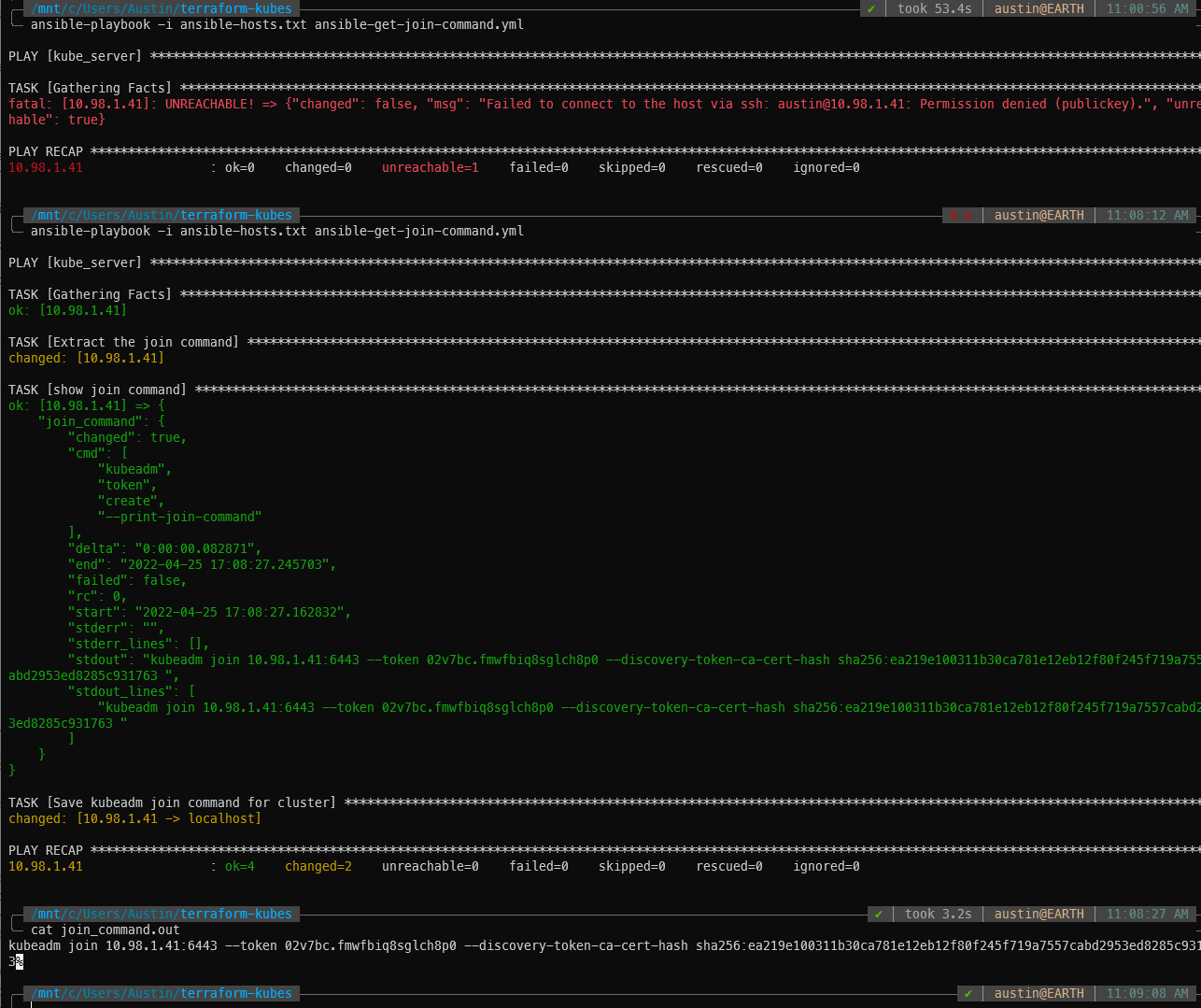
With the master up and running, we need to retrieve the join command. I chose to save the command locally and read the file in a subsequent Ansible playbook. This could certainly be combined into a single playbook.
ansible-get-join-command.yaml –
- hosts: kube_server
become: false
remote_user: ubuntu
vars_files:
- ansible-vars.yml
tasks:
- name: Extract the join command
become: true
command: "kubeadm token create --print-join-command"
register: join_command
- name: show join command
debug:
var: join_command
- name: Save kubeadm join command for cluster
local_action: copy content={{ join_command.stdout_lines | last | trim }} dest={{ join_command_location }} # defaults to your local cwd/join_command.out
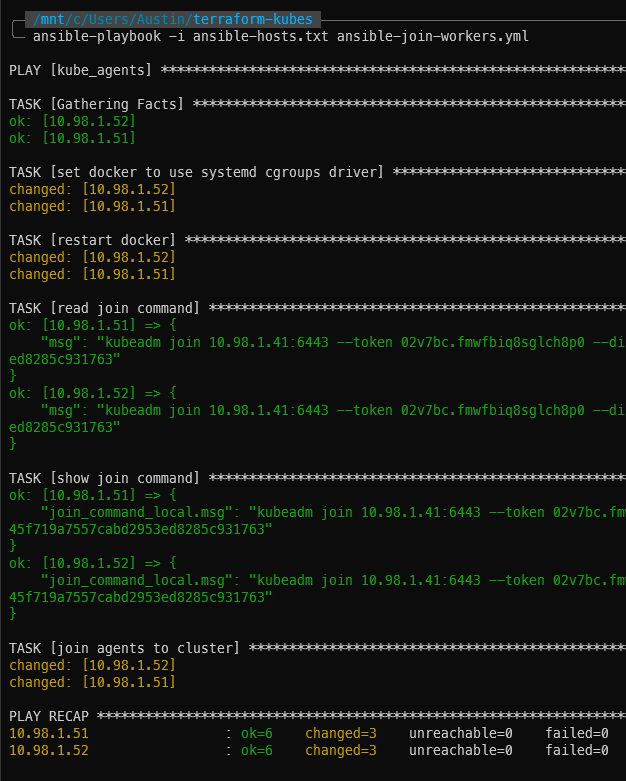
Two worker agents successfully joined to the cluster
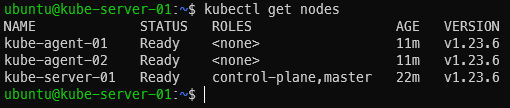
With the two worker nodes/agents joined up to the cluster, you now have a full on Kubernetes cluster up and running! Wait a few minutes, then log into the server and run kubectl get nodes to verify they are present and active (status = Ready):
kubectl get nodes
‘kubectl get nodes’ showing our nodes as ready
Kubernetes Dashboard
Everyone likes a dashboard. Kubernetes has a good one for poking/prodding around. It appears to basically be a visual representation of most (all?) of the “get information” types of command you can run with kubectl (kubectl get nodes, get pods, describe stuff, etc.).
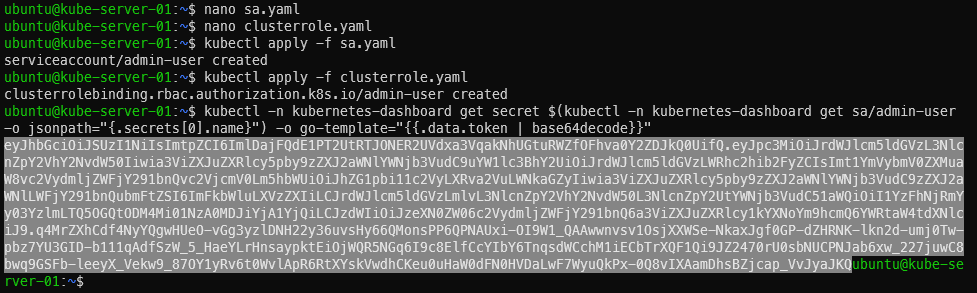
The dashboard was installed with the cluster init script but we still need to create a service account and cluster role binding for the dashboard. These steps are from https://github.com/kubernetes/dashboard/blob/master/docs/user/access-control/creating-sample-user.md. NOTE: the docs state it is not recommended to give admin privileges to this service account. I’m still figuring out Kubernetes privileges so I’m going to proceed anyways.
Dashboard user/role creation
On the master machine, create a file called sa.yaml with the following contents:
Apply both, then get the token to be used for logging in. The last command will spit out a long string. Copy it starting at ‘ey’ and ending before the username (ubuntu). In the screenshot I have highlighted which part is the token
Applying both templates and getting the user’s token
SSH Tunnel & kubectl proxy
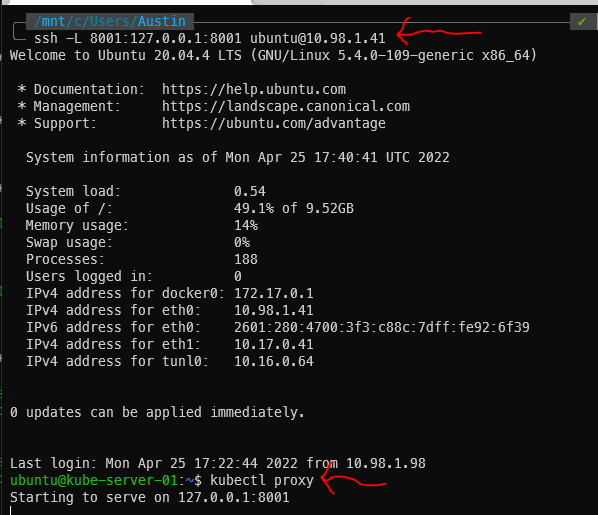
At this point, the dashboard has been running for a while. We just can’t get to it yet. There are two distinct steps that need to happen. The first is to create a SSH tunnel between your local machine and a machine in the cluster (we will be using the master). Then, from within that SSH session, we will run kubectl proxy to expose the web services.
SSH command – the master’s IP is 10.98.1.41 in this example:
The above command will open what appears to be a standard SSH session but the tunnel is running as well. Now execute kubectl proxy:
Kubernetes SSH tunnel & kubectl proxy output
The Kubernetes Dashboard
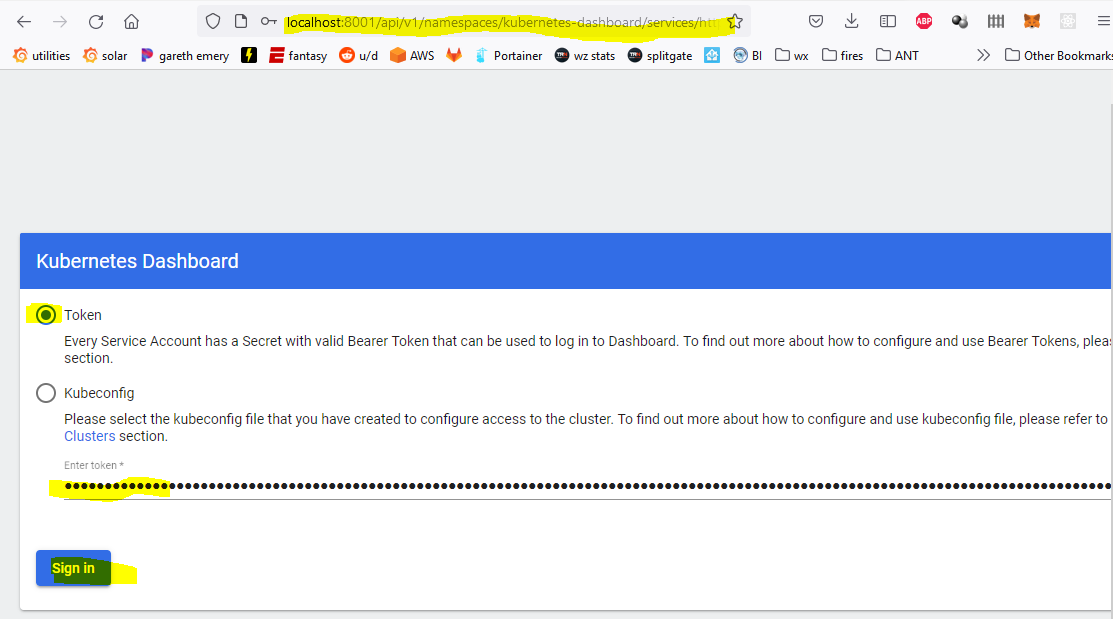
At this point, you should be able to navigate to the dashboard page from a web browser on your local machine (http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/) and you’ll be prompted for a log in. Make sure the token radio button is selected and paste in that long token from earlier. It expires relatively quickly (couple hours I think) so be ready to run the token retrieval command again.
Kubernetes dashboard login with token
The default view is for the “default” namespace which has nothing in it at this point. Change it to All namespaces for more details:
Kubernetes dashboard all namespaces
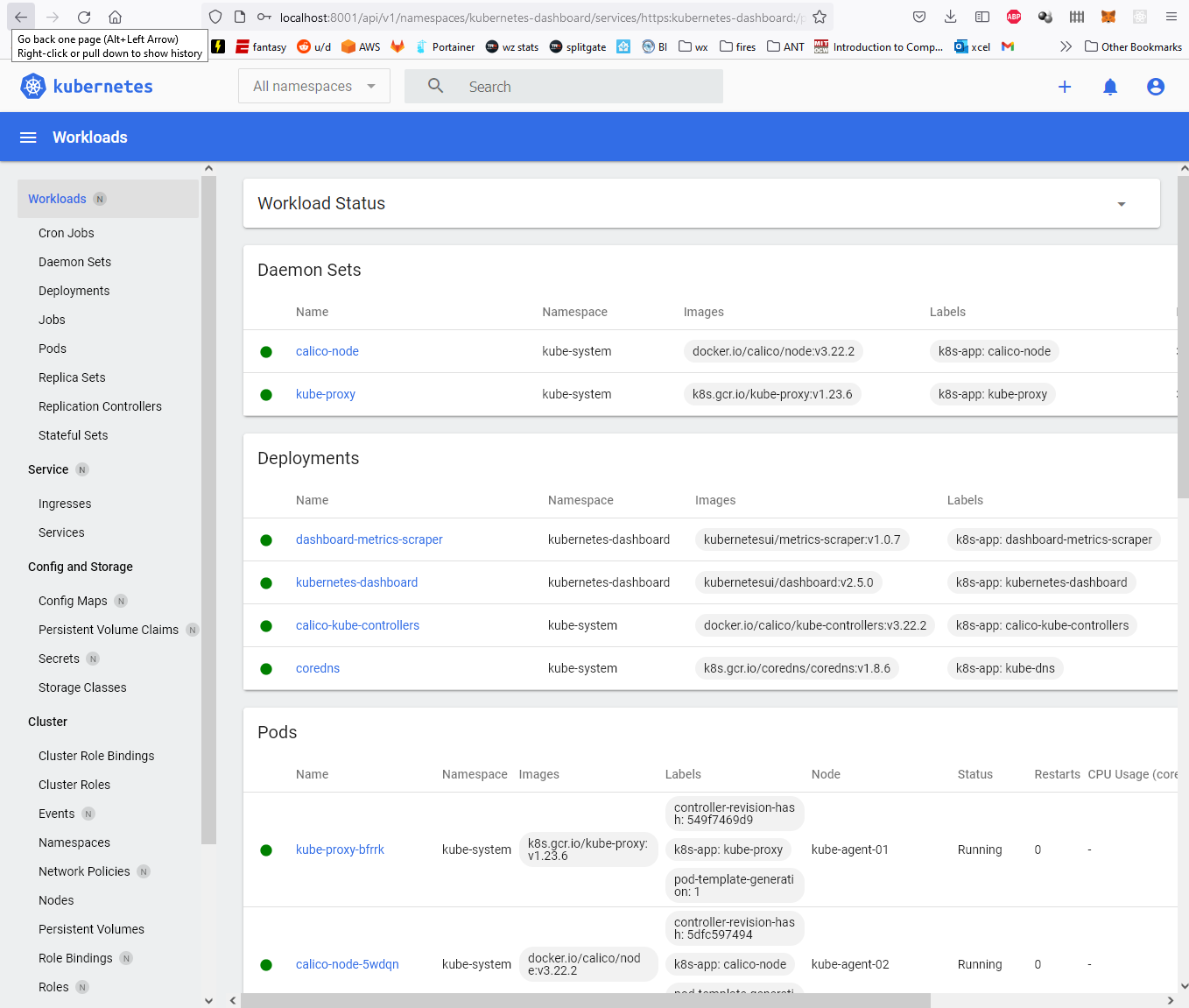
From here you can see information about everything in the cluster:
My main use for MacOS VM is to use Apple’s XCode for basic app development (Swift, SwiftUI, UIKit, React Native, etc.) in a fairly fast environment. I have a slower actual Mac for publishing and such but like the flexibility of working in a virtual environment within Proxmox.
I’m still thinking about writing a script to automate the deployment – keep checking back if you’re interested!
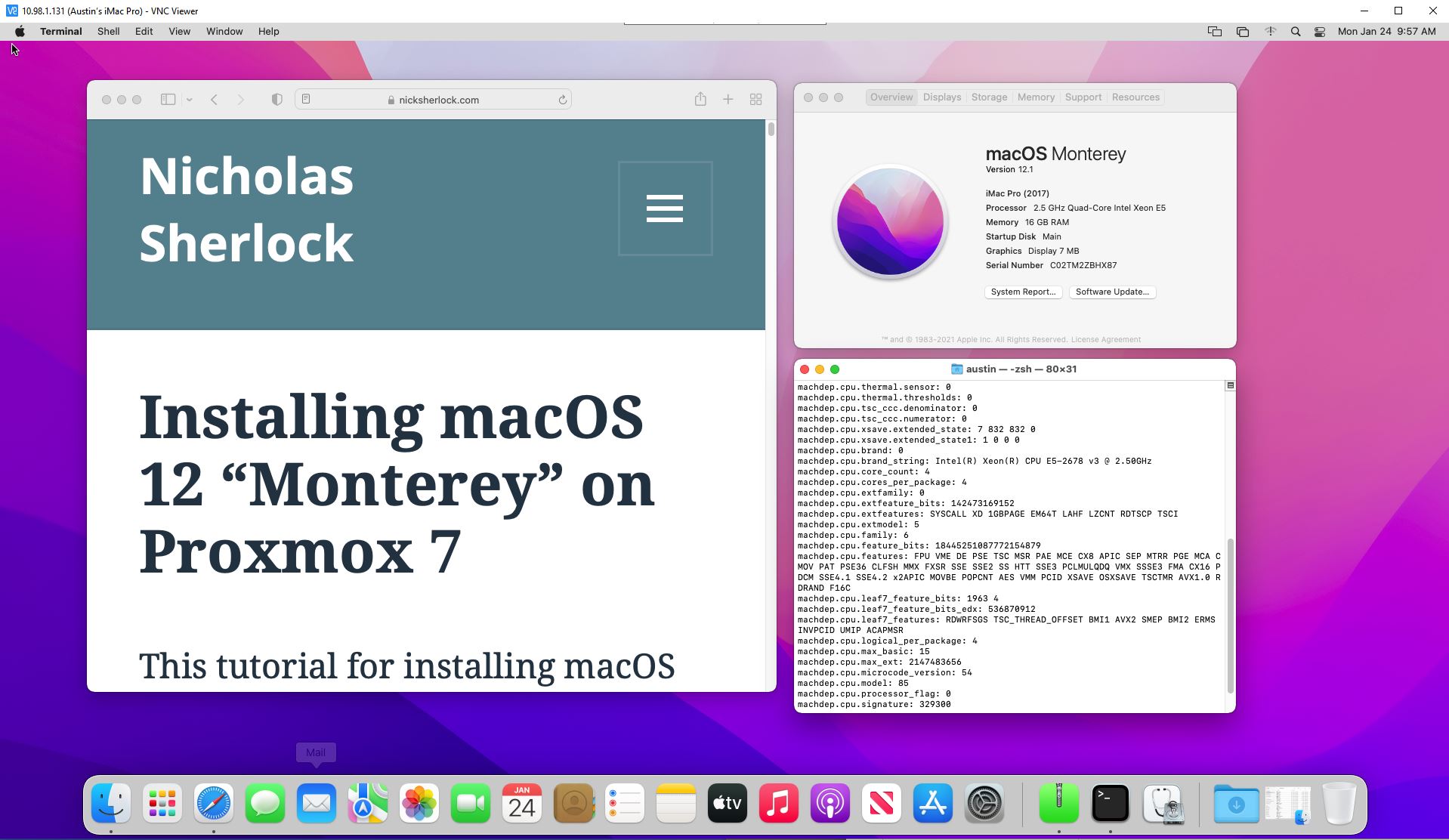
Here’s a picture of the environment showing my Xeon e5-2678v3 as the processor in the MacOS desktop:
MacOS Monterey running in a Proxmox virtual machine for Xcode
For Part 2, which includes activities such as setting your MacOS Monterey VM to automatically boot, consolidating the OpenCore bootloader disk, reviewing the procedure for activating your Mac VM, please click the following link: https://www.youtube.com/watch?v=oF7n2ejdTPU
Without further ado, below is the template I used to create my virtual machines. The main LAN network is 10.98.1.0/24, and the Kube internal network (on its own bridge) is 10.17.0.0/24.
This template creates a Kube server, two agents, and a storage server.
Update 2022-04-26: bumped Telmate provider version to 2.9.8 from 2.7.4